
Выясняем, как рассуждают датасаентисты: зачем иногда писать в личку бывшим, как не получить по щам и что делать, если хочешь удивить мир.
Идеи, лежащие в основе загадочной и неприступной Data Science, не такие уж и сложные. Возможно, некоторые из них вы давно применяете в повседневной жизни. Если нет — самое время попробовать.
Содержание
🎯 самые полезные лайфхаки в мини-формате обитают в нашем telegram. постим раз в день, коротко и по делу.
Недообучение, или Чтобы провал не был полным
Модель машинного обучения нужна для того, чтобы восстановить (смоделировать) какой-то реальный процесс по информации, которая о нем имеется.
Самый простой пример: приближенное восстановление неизвестных значений функции по имеющимся точкам графика. Это хорошо работает, когда точек достаточно. Если же их всего две, получится прямая линия, которая, скорее всего, не совпадает с искомой функцией. Если три — результат будет лучше, но всё равно слишком далек от нужного.

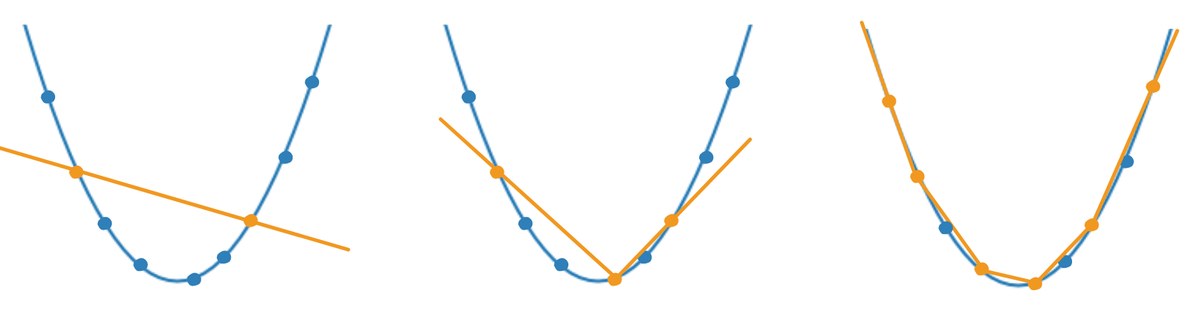
В таких случаях говорят, что модель, восстанавливающая график, недообучена. На практике это равносильно либо тому, что она почему-то использует не все данные, либо данных просто недостаточно. А, полный провал, как известно, начинается именно с неполных данных.
В жизни:
- Во-первых, не делайте выводов, если информации мало. Тщательно изучите тему. Выслушайте другую сторону. Прочитайте, наконец, инструкцию!
- Во-вторых, если есть возможность, не давайте никому всю информацию о себе. (Особенно IP-адрес. Олды поймут).
Сами при этом старайтесь собрать как можно более полные данные обо всём, что вас непосредственно касается.
Разработка признаков, или Сила в переменных
Признаки в Data Science, или, как их ещё называют, переменные, представляют собой одну из множества колонок в таблице из чисел и символов. Перед построением модели машинного обучения дата-сайентист решает, какие, собственно, колонки должна учитывать модель, чтобы сделать предсказание, классифицировать данные или принять решение.
Этот этап — разработка признаков — наиболее творческая часть работы дата-сайентиста. Здесь творится главная магия: реальность превращается в данные, и от качества этого превращения будет зависеть всё. Например, для определения стоимости квартиры имеют значение расстояние до метро, площадь и планировка. Значит, эти переменные обязательно должны учитываться моделью.
В жизни:
Определите приоритеты и выделите главные признаки, которые будут влиять на ваши решения. Чем точнее определены признаки — то есть выбраны значимые и отброшены незначимые — тем лучше будет работать ваша внутренняя модель предсказания и принятия решений.
Переобучение, или Синдром отличника
Модели машинного обучения не рождаются сразу готовыми. Сначала их обучают на тренировочной выборке, а затем проверяют качество обучения на тестовом датасете. Часто бывает так, что на тренировочной выборке модель показывает блестящие результаты, а на тестовой с треском проваливается. Тогда говорят, что модель переобучена.
Можно заставить модель определения стоимости квартиры учитывать не только район и площадь, а, например, ещё и цвет обоев, и материал входной двери. Тогда на тренировочной выборке она будет очень точно определять цену. А на тестовой, когда попадутся квартиры, которых модель не видела, скорее всего, результат будет так себе — из-за влияния незначимых переменных.

В жизни:
Не зацикливайтесь на решении одних и тех же задач. В Data Science процентное соотношение обучающей и тестовой выборки обычно 70:30, 75:25 или 80:20. То есть имеет смысл посвятить примерно четверть вашего времени изучению чего-то нового — так вы снизите риск провала при встрече с незнакомыми проблемами.
Во всяком случае, примерно так рассуждают дата-сайентисты. Мы же верим дата-сайентистам?
Reject Inference, или «Нет» — это не навсегда
Модель машинного обучения, встроенная в систему скоринга, решает, выдавать кредит или нет. При этом человек, которому отказали в кредите, может получить деньги в другом месте. Более того, он может оказаться добросовестным заёмщиком, а это прямой убыток первому банку — в виде недополученной прибыли.
Чтобы улучшить работу своих моделей, кредитные организации закупают данные о таких «отказниках» и добавляют их в обучающие выборки. Это и есть, вкратце, суть метода reject inference.
Схожие методы борьбы со смещением данных применяют и в других отраслях, например в онлайн-маркетинге, биржевом трейдинге и даже компьютерном зрении.
В жизни:
Полезно периодически вспоминать об отброшенных вариантах (писать бывшим в личку) и пересматривать их в свете новых обстоятельств. Так вы улучшите свою внутреннюю модель — узнав, правильно она предсказывала раньше или нет, и внеся соответствующие поправки.
Знание отрасли, или Сами мы не местные
Дата-сайентисту мало уметь работать с числами и данными. Ещё нужно хорошо понимать тот участок реальности, который он превращает в числа и данные. Без этого понимания переменные будут слабыми, модель не будет схватывать задачу правильно, а результат не будет иметь смысла. Не за это ему столько платят!
Поэтому, прежде чем внедрять машинное обучение и прочие нейронки на GPT-3, дата-сайентист тратит кучу времени, чтобы разобраться в том, что именно влияет или может повлиять на исследуемый процесс или явление. А это, в свою очередь, требует кругозора, опыта и привычки размышлять.

В жизни:
Прежде чем внедрять свою модель принятия решений в чужой монастырь, потратьте немного времени на то, чтобы понять, насколько она здесь уместна. Иначе рискуете получить по щам. А это, скорее всего, совсем не тот результат, которого вы ожидаете.
Короче, будьте эрудированными, опытными и сообразительными, а то как эти 😊
TL;DR
Data Science битком набита красивыми и мощными идеями, каждая из которых может быть осмыслена и годится для использования в самой обычной жизни.
Снижение размерности, площадь под кривой ошибок, градиентный спуск, обратное распространение ошибки, опорные векторы, метод К-средних — если с помощью этих методов дата-сайентисты успешно решают сложные проблемы науки, бизнеса и промышленности, то почему бы не применить их принципы и к нашим ежедневным задачам?
Как именно — мы обязательно расскажем в будущем, если эта публикация вам понравится. В общем, to be continued.
Почитать bubble в микро- и даже наноформате можно в instagram. подключайтесь 🤳









